Can AI Conduct AI Research Experiments?
Patrick Tser Jern Kon*,
Jiachen Liu* (Equal Contribution*)
Xinyi Zhu,
Qiuyi Ding,
Jingjia Peng (University of Michigan),
Jiarong Xing (UC Berkeley & Rice University),
Yibo Huang (University of Michigan),
Yiming Qiu (UC Berkeley & University of Michigan),
Jayanth Srinivasa,
Myungjin Lee (Cisco Research),
Mosharaf Chowdhury (University of Michigan),
Matei Zaharia (UC Berkeley),
Ang Chen (University of Michigan)
AI for Science is rapidly advancing, with promising early work on scientific automation—such as DeepMind’s AlphaEvolve and others highlighted in this Nature paper. A particularly exciting frontier is the automation of AI research experimentation—the process of designing, executing, and analyzing experiments to advance AI itself. Unlike fields requiring physical experimentation, AI research is largely digital—well-suited for LLM-based automation.
Ideally, we want to provide an AI agent with a research goal—such as reproducing a result, validating a new hypothesis, or testing an ablation— along with the specific context and have the agent:
- • Formulate hypotheses, design experiments,
- • Interpret the associated codebase and identify how to modify it,
- • Configure and execute experiments under the right conditions,
- • Analyze results and iteratively refine its approach based on findings

Figure 1. EXP-Bench evaluates AI agents on research experiment tasks extracted semi-autonomously from peer-reviewed AI papers.
Achieving this vision requires benchmarks that evaluate agents in real-world research scenarios. But how do we define those scenarios in a way that’s representative, reproducible, and gradable?
Intuitively, peer-reviewed AI papers (e.g., in NeurIPS) along with their open-source codebases, offer a rich source of completed experiments that could, in theory, be repurposed to evaluate AI capabilities in research automation. In practice, however, extracting these tasks is difficult. Papers often present a polished narrative that omits intermediate steps, while critical details—such as the precise conditions under which results hold—are scattered across dense text, supplementary materials, and sprawling repositories.
Our Contribution: EXP-Bench
To address this challenge, we introduce EXP-Bench, a new benchmark designed to make the ever-expanding landscape of published research more accessible for evaluating AI agents in conducting end-to-end AI research experiments—from hypothesis to experimental setup to conclusion, as shown in Figure 1. We develop a semi-automated pipeline (Figure 2) that uses multimodal and agentic approaches to reconstruct experiments from fragmented and dense sources (e.g., coding agents identify setups by conditioning on ground-truth outcomes and leveraging the full codebase—reducing the task to a constrained search), while interleaving these steps with lightweight human validation to ensure correctness.
Using this approach, we distilled 461 experiments from NeurIPS and ICLR papers—spanning domains such as vision, RL, and computational biology—resulting in over 12,000 gradable subtasks.
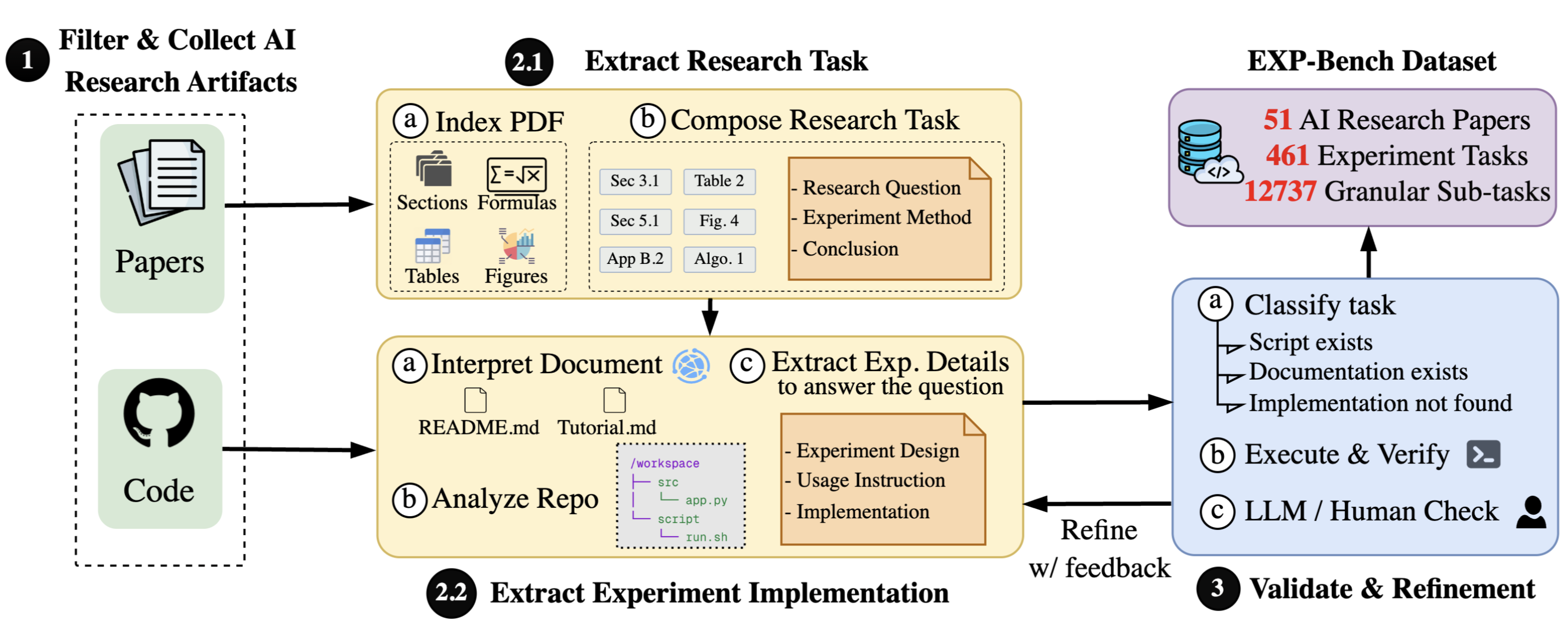
Figure 2. Our semi-automated pipeline for constructing EXP-Bench from published papers.
See Figure 3 for an example AI research task extracted through this pipeline.

Figure 3. One AI research task example from ICLR 2024 MogaNet [1].
What EXP-Bench Reveals About Today’s AI Agents
We tested leading agents, including OpenHands w/ Claude Sonnet 3.7, and found that while they can earn partial credit for individual steps like experiment design or coding (~20-35% success), their ability to complete a full, executable experiment is nearly non-existent—a mere 0.5% success rate.
Our analysis pinpointed several critical weaknesses:
- Limited Long-Horizon Planning and Reasoning
- Inability to Handle Open-Ended and Ambiguous Tasks (35.9%)
- Difficulty with Environment Setup (41.3%) and Code Debugging (29.8%)
These results highlight just how far we still are from our goal of automation of research experimentation. By identifying these bottlenecks and providing realistic step-by-step experiment procedures, EXP-Bench serves as a vital tool for future AI agents to improve their ability to conduct AI research experiments.
Looking Forward
This work is, we hope, a small step toward our broader goal of designing agents capable of automating scientific research. We see EXP-Bench as a launchpad for the next wave of AI research copilots.
That said, much work remains. While EXP-Bench currently focuses on machine learning papers, it does not yet address domains that require interaction with the physical world or support tasks involving true scientific invention. Expanding to those areas—and capturing the creativity, uncertainty, and iteration of real-world discovery—remains an open and exciting challenge.
Explore Our Work
@article{kon2025expbenchaiconductai,
title={EXP-Bench: Can AI Conduct AI Research Experiments?},
author={Patrick Tser Jern Kon and Jiachen Liu and Xinyi Zhu and Qiuyi Ding and Jingjia Peng and Jiarong Xing and Yibo Huang and Yiming Qiu and Jayanth Srinivasa and Myungjin Lee and Mosharaf Chowdhury and Matei Zaharia and Ang Chen},
journal={arXiv preprint 2505.24785}
year={2025},
}
[1] MogaNet: Multi-order Gated Aggregation Network. ICLR 2024